MIT AI Hardware Program
2024 Symposium
Wednesday, May 1, 2024 | 9:30am - 3:00pm ET
MIT Schwarzman College of Computing
51 Vassar St, 8th Floor
Cambridge, MA 02139
Hybrid Event

About
The MIT AI Hardware Program is an academia-industry initiative between the MIT School of Engineering and MIT Schwarzman College of Computing. We work with industry to define and bootstrap the development of translational technologies in hardware and software for the AI and quantum age.
The symposium includes project reviews of the current MIT AI Hardware Program portfolio as well as exposure to new projects.

Register
Registration for this event is closed.
Agenda
9:30 – 10:00
Registration and Breakfast
10:00 - 10:05
Year in Review & the Year Ahead
Program Co-Leads
Jesús del Alamo, Donner Professor; Professor, Electrical Engineering and Computer Science; MacVicar Faculty Fellow
Aude Oliva, Director of Strategic Industry Engagement, MIT Schwarzman College of Computing; CSAIL Senior Research Scientist

10:05 – 10:50 | Keynote
A Pathway to Safer, Personalized and Aligned Foundation Models
Pulkit Agrawal, Associate Professor, Electrical Engineering and Computer Science
Today, large models like LLMs are aligned to an average user. In the future, there will be hundreds of foundation models for different domains, and there will be a need to personalize these models for users. Today, verifying models requires recruiting teams of human testers, and alignment methods are not well suited for personalization and often require access to model weights which may not be available. In this talk, I will describe a scalable pathway to model alignment, model personalization and automatic verification that makes testing models prior to deployment cheaper and faster.

10:50 – 11:50 | Project Reviews
Enhancing Microprocessor Reliability
Peter Deutsch and Vincent Ulitzsch, PhD Candidates, Electrical Engineering and Computer Science
We aim to create models for new fault modes in processors, addressing reliability challenges for large-scale data centers. Our research develops methods for designing resilient hardware, guiding cost-effective protection strategies for scalability.
In collaboration with Mengjia Yan, Assistant Professor of Electrical Engineering and Computer Science and Joel S. Emer, Professor of the Practice, Electrical Engineering and Computer Science

Tailors: Accelerating Sparse Tensor Algebra by Overbooking Buffer Occupancy
Fisher Zi Yu Xue, PhD Candidate, Electrical Engineering and Computer Science
Optimization methods for deep neural networks (DNNs) often introduce models with various sparsity characteristics. In our work, we propose a software-hardware co-design methodology to efficiently support DNNs with weights and activations that are either fully dense or sparse with various degrees of sparsity.
In collaboration with Vivienne Sze, Associate Professor of Electrical Engineering and Computer Science and Joel S. Emer, Professor of the Practice, Electrical Engineering and Computer Science

Analog Based CNN Accelerator with RRAMs
Aya Amer, Postdoctoral Associate, Research Laboratory of Electronics
This work presents a compute-near-RRAM analog classifier architecture, leveraging the fine-grained monolithic 3D integration of non-volatile RRAM memory over silicon CMOS. New circuit design techniques are proposed to overcome RRAM variations and to perform energy-efficient analog computations that overcome ADCs and DACs energy and delay overheads in the conventional architectures. A highly parallel analog architecture for CIFAR10 image classification is presented by integrating the proposed designs achieving >300x improved energy-delay product than previous implementations.
In collaboration with Anantha Chandrakasan, Dean of the School of Engineering and Vannevar Bush Professor of Electrical Engineering and Computer Science

Applying Artificial Intelligence to Electronic Design
Ruonan Han, Associate Professor, Electrical Engineering and Computer Science
While the recent advances in generative AI and large language model have shown great potential in assisting with many scientific and engineering problems, it is not clear yet if and how such advances may benefit integrated-circuit chip designs. In particular, design automation for analog and RF circuits has not been successful over the past few decades, and designers still heavily rely on their experience and insight when it comes to topology selection, optimization, etc. Will the new intelligence brought by large language models, especially after retrieval-augmented generation with well curated data, change the landscape of analog/RF electronic design? In this MIT-ADI collaborative project started 7 months ago, we are trying to investigate into this space.

11:50 – 12:45
Lunch
12:45 – 2:00 | Project Reviews
CMOS-Compatible Ferroelectric Synapse Technology for Analog Neural Networks
Yanjie Shao, Postdoctoral Associate, Research Laboratory of Electronics
The recent discovery of prominent ferroelectric properties of CMOS-compatible HfO2-based materials has brought new functionality to microelectronics in the form of a new memory technology and the potential of transistors that can operate at very low voltages. An intriguing new application of these remarkable findings is in low-energy analog synapses.
In collaboration with Jesús del Alamo, Donner Professor; Professor, Electrical Engineering and Computer Science; MacVicar Faculty Fellow

TinyChat: Visual Language Models & Edge AI 2.0
Song Han, Associate Professor, Electrical Engineering and Computer Science
This talk will explore the latest advancement in TinyChat and AWQ – the integration of Visual Language Models (VLM). The exciting advancements in VLM allows LLMs to comprehend visual inputs, enabling seamless image understanding tasks like caption generation, question answering, and more. With the latest release, TinyChat now supports leading VLMs such as VILA, which can be easily quantized with AWQ, empowering users with seamless experience for image understanding tasks.

Compiling Deep Learning Tasks onto (Quantum-) Optical Systems
Dirk Englund, Associate Professor, Electrical Engineering and Computer Science
The field of quantum mechanics presents significant opportunities to tackle unresolved issues in communication, computation, and precision measurement. We are working to advance these technologies in diverse physical systems, such as atoms, superconductors, and topological states of matter.

3D and Space Representation
Vincent Sitzmann, Assistant Professor of Electrical Engineering and Computer Science
Prof. Sitzmann’s Scene Representation Group investigates generative modeling for 3D scene generation, 3D scene completion, 3D editing, computer graphics, and animation. His research combines differentiable rendering and scene representation techniques with novel generative architectures that have 3D structure built-in, enabling data-efficient and interpretable generative modeling.

Diffusion Models as Data Generator for Visual AI Models
Phillip Isola, Associate Professor of Electrical Engineering and Computer Science
We describe a simple approach where we use a diffusion model to generate the training data for a vision system. The traditional approach is to scrape data from the internet, or other repositories of real photos, then use these photos to train a visual representation. Instead, we scrape data from a diffusion model, searching through the model’s hallucinations to collect synthetic images that can train vision. We study the current limits of this approach and discuss several advantages it can have over using real data.

2:00 – 3:00 | Research Showcase
This in-person session will feature interactive demos and posters. Refreshments will be provided.
Demo Gallery
Interact with the research in this showcase of cutting-edge technologies.
TinyChat: An AI System in Your Hand
This demo presents TinyChat, an efficient model for running large language models (LLMs) locally on the edge. The key technique is 4-bit AWQ model quantization. It’s being used by IBM, NVIDIA, and Intel.
Presented by: Wei-Chen Wang, Haotian Tang, and Shang Yang from the MIT HAN Lab. With Song Han, Associate Professor of Electrical Engineering and Computer Science.

High-Fidelity Diagnostics through WiFi
This demo illustrates how WiFi signals can be used to assess the presence of agents in an environment and shows applications of the research to healthcare and the diagnostics of brain diseases.
Presented by: Ali Mirzazadeh from the NETMIT Research Group. With Dina Katabi, Thuan and Nicole Pham Professor of Electrical Engineering and Computer Science.

Neural Scene Representation
In this demo, you will see AI create detailed 3D models of entire scenes: this includes transforming videos into 3D spaces in a single step and reconstructing complete 3D objects from 2D images.
Presented by David Charatan and Sizhe Lester Li from the Scene Representation Group. With Vincent Sitzmann, Assistant Professor of Electrical Engineering and Computer Science.

Let’s Play Soccer
In this demo, you will be able to play with Dribblebot, a legged robotdesigned to dribble a soccer ball. This research demonstrates that quadrupeds can effectively handle dynamic control tasks involving both movement and manipulation.
Presented by Nolan Edward Fey from the Improbable AI Lab. With Pulkit Agrawal, Associate Professor of Electrical Engineering and Computer Science.

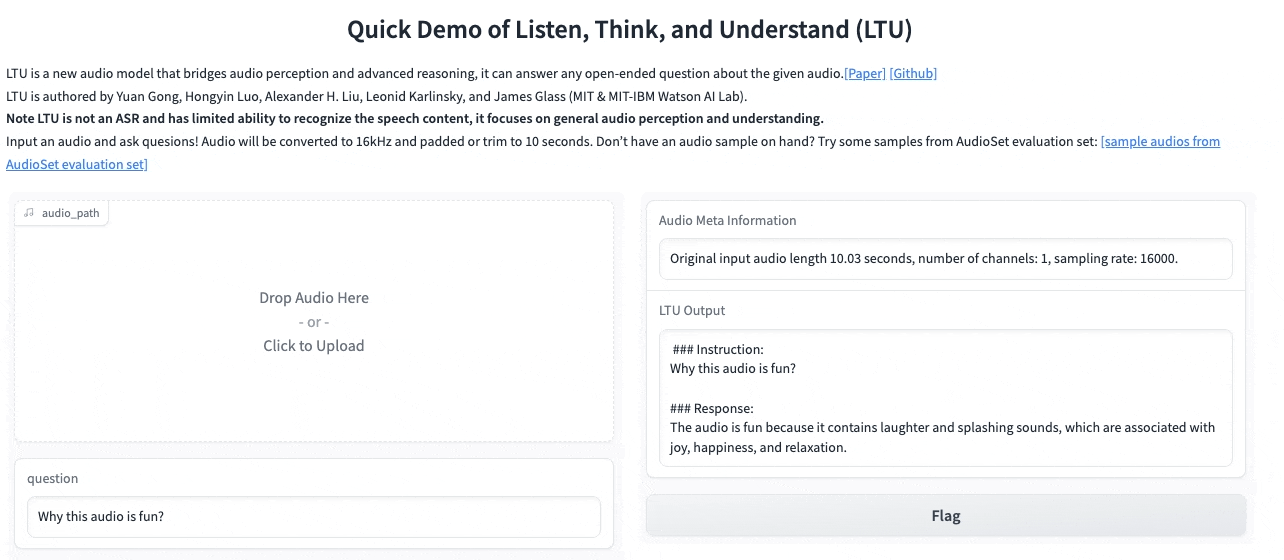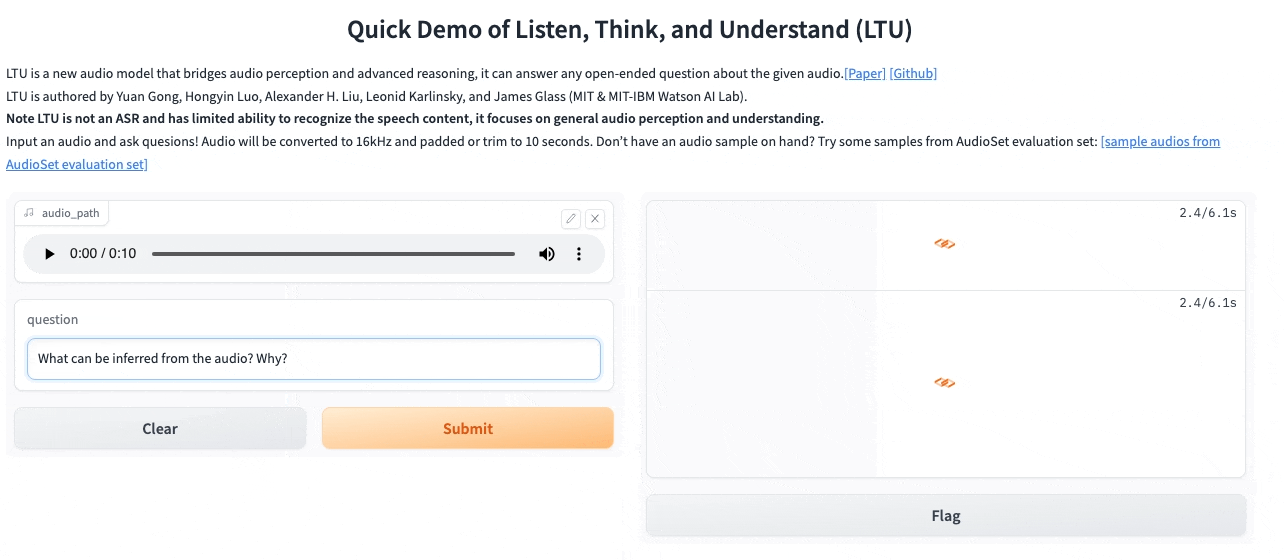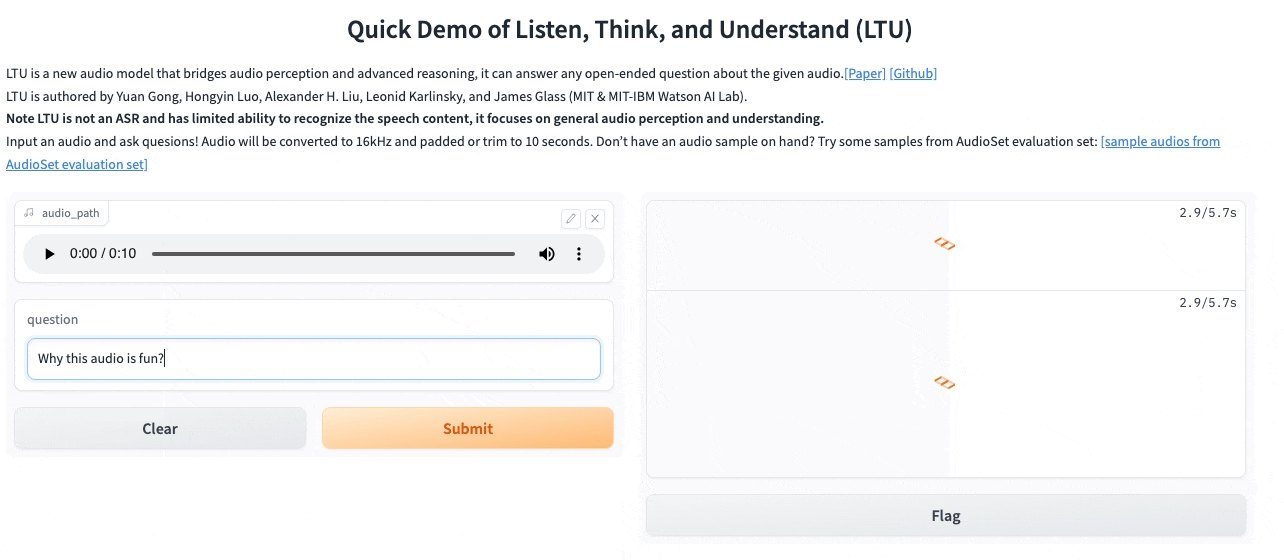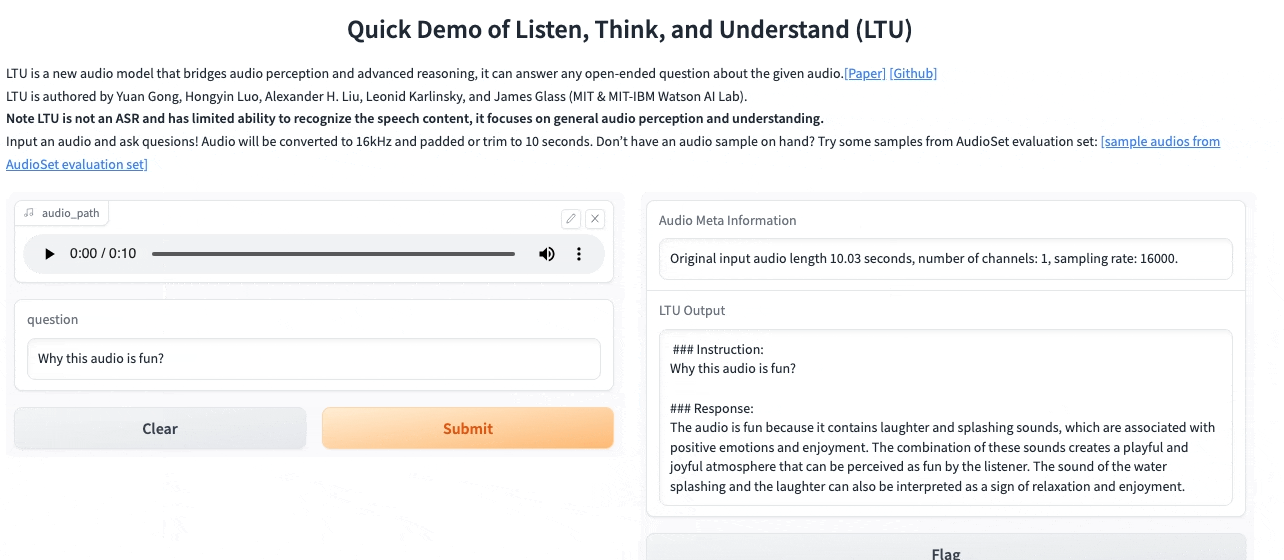
Listen, Think, and Understand
In this demo, you will be able to interact with LTU, our audio large language model that can jointly recognize, understand, and converse about any speech, paralinguistics (e.g., emotion) and general audio that it listens to.
Presented by: Yuan Gong, Alex Liu, and Hongyin Luo from the Spoken Language System group. With Jim Glass, Senior Research Scientist at the Computer Science & Artificial Intelligence Lab.
A Secure Digital In-Memory Chip
This demo presents a general method for secure machine learning hardware using a digital in-memory compute architecture through decorrelation of circuit currents from neural network data, encrypting off-chip model storage, and local secret key generation.
Presented by: Maitreyi Ashok from the Energy-Efficient Circuits and Systems Group. With Anantha Chandrakasan, Dean of MIT’s School of Engineering and Vannevar Bush Professor of Electrical Engineering and Computer Science.

Can I Walk Your Dog?
Watch this robotic dog trained via deep reinforcement walk up the stairs. The robot dog utilizes a depth camera to adapt its training to the different levels and surfaces it encounters.
Presented by Ge Yang from the Embodied Intelligence and Visual Computing Group. With Phillip Isola, Associate Professor of Electrical Engineering and Computer Science.

Can I Hold Your Coffee?
In this demo, you will be able to tell a robotic arm what object to pick up. This project focuses on language-guided manipulation that generalizes across objects in the real world.
Presented by Ge Yang, William Shen, and Ishaan Chandratreya from the Embodied Intelligence and Visual Computing Group. With Phillip Isola, Associate Professor of Electrical Engineering and Computer Science.

Poster Session

CMOS-Compatible Ferroelectric Synapse Technology for Analog Neural Networks
Yanjie Shao, Jesus del Alamo
Artificial intelligence (AI) has irreversibly changed the way information is stored and processed. However, the huge energy consumption and enormous computation time required for training modern deep learning models highlights the urgent need of energy- and time-efficient hardware uniquely designed to implement AI algorithms. Recently, analog computing has been proposed as an alternative to the digital counterpart. In this work, we examine the potential of ferroelectric field-effect transistors (FE-FETs) as the core device for analog accelerators. We have fabricated FE-FETs using FE-Hf0.5Zr0.5O2 (HZO) and a metal oxide channel, within a CMOS-compatible thermal budget of ≤400 °C. This work shows the great potential of ferro-electronics for analog AI hardware.

LoopTree: Exploring the Fused-layer Dataflow Accelerator Design Space
Michael Gilbert, Vivienne Sze, Joel Emer
Many accelerators today process deep neural networks layer by layer. As a consequence of this processing style, every intermediate feature map incurs expensive off-chip transfers. Layer fusion eliminates off-chip transfers of intermediate results, leading to better latency and energy efficiency. Prior works have explored only subsets of the fused-layer design space, looking only at a particular choice of tiling, scheduling, and buffering strategy. Their architectural models are also tailored for their proposed datatlow. The lack of a unified, systematic representation of designs and a versatile evaluation method has prevented thorough exploration of the design space. To enable systematic exploration of this design space, we present LoopTree, a framework for describing and evaluating any design in our expanded fused-layer datatlow design space. With a case study, we explore new designs to show that exploring our larger design space uncovers more efficient designs, especially for recent workloads with diverse layer types. Our design achieves 2.5× speedup and 2× lower energy compared to an optimized layer-by-layer design. Compared to a state-of-the-art fused-layer design, we match latency and energy while using 25% less onchip buffer space.

RAELLA: Reforming the Arithmetic for Efficient, Low-Resolution, and Low-Loss Analog PIM: No Retraining Required!
Tanner Andrulis, Vivienne Sze, Joel Emer
Processing-In-Memory (PIM) accelerators have the potential to efficiently run Deep Neural Network (DNN) inference by reducing costly data movement and by using resistive RAM (ReRAM) for efficient analog compute. Unfortunately, overall PIM accelerator efficiency is limited by energy-intensive analog-to-digital converters (ADCs). Furthermore, existing accelerators that reduce ADC cost do so by changing DNN weights or by using low-resolution ADCs that reduce output fidelity. These strategies harm DNN accuracy and/or require costly DNN retraining to compensate.
To address these issues, we propose the RAELLA architecture. RAELLA adapts the architecture to each DNN; it lowers the resolution of computed analog values by encoding weights to produce near-zero analog values, adaptively slicing weights for each DNN layer, and dynamically slicing inputs through speculation and recovery. Low-resolution analog values allow RAELLA to both use efficient low-resolution ADCs and maintain accuracy without retraining, all while computing with fewer ADC converts.
Compared to other low-accuracy-loss PIM accelerators, RAELLA increases energy efficiency by up to 4.9× and throughput by up to 3.3×. Compared to PIM accelerators that cause accuracy loss and retrain DNNs to recover, RAELLA achieves similar efficiency and throughput without expensive DNN retraining.

Foundry-Scalable Phase Change Optical Memristors for Versatile Photonic Computing Architectures
Maarten R.A. Peters, Carlos A. Rios Ocampo, Juejun Hu
Optical memristors are devices capable of modulating the light amplitude and holding the state in a non-volatile manner. These are crucial characteristics of computing and storing multi-bit data in analog photonic computing. Recent years have seen materials and platforms achieving outstanding proof of concept for such a device. Among them, phase change materials (PCMs) have demonstrated huge potential due to their large modulation of optical properties, substrate blindness, previously demonstrated commercial success, low cost, and true nonvolatility. However, current state-of-the-art demonstrations, are still at the device level and fabricated mostly in university cleanrooms, giving limited scalability and information on reliability. We will overcome this by pioneering a high-yield, scalable, backend-of-line (BEOL) foundry process to integrate large numbers of PCM optical memristors and enable reconfigurable photonic processors. We will explore two main architectures for high-throughput MAC operation: 1) The photonic crossbar array depicted in with optical memristors at each column-row intersection for intensity modulation. 2) An MZI mesh with optical memristors at different stages performing phase modulation.

SecureLoop: Design Space Exploration of Secure DNN Accelerators
Kyungmi Lee, Anantha Chandrakasan
SecureLoop is a framework for design space exploration of secure DNN accelerators equipped with a hardware support for cryptographic operations. The goal of SecureLoop is to enable a systematic investigation of the performance, area, and energy trade-off for supporting a TEE in diverse DNN accelerator designs. We propose a scheduling search engine that identifies the optimal mapping of a DNN workload to a given hardware, such that a fair comparison among diverse designs can be achieved.

DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Muyang Li, Song Han
Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naively implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1× speedup on eight A100 GPUs compared to one.

Inverse Design in Nanoscale Devices
Davide Bray, Giuseppe Romano
We propose the development of a differentiable physics solver to optimize electronic and thermal transport in nanoscale devices. This tool will enable constrained large-scale shape optimization of systems with prescribed proprieties, opening up opportunities for novel computing architectures and software and hardware co-optimization.