
Principal Investigator: Song Han
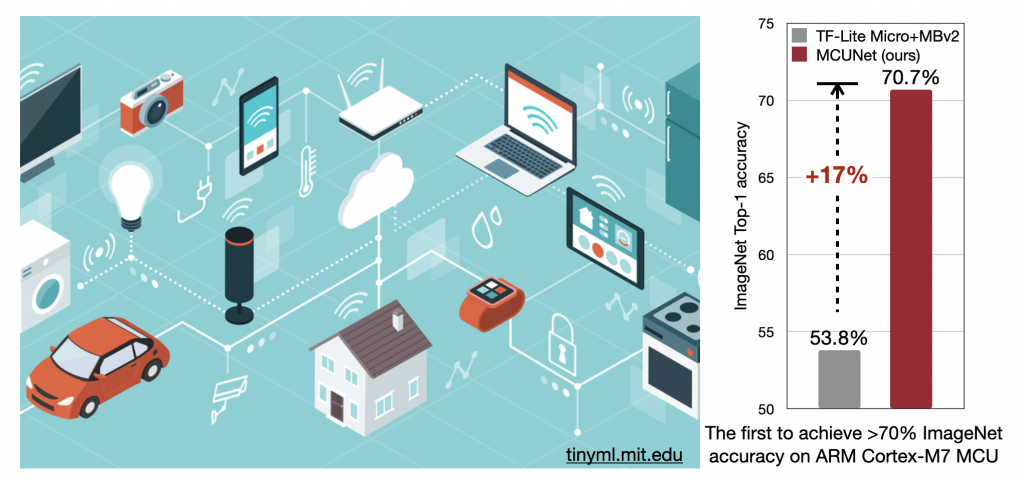 Modern deep learning requires a massive amount of computational resource, carbon footprint, and engineering efforts. On mobile devices, the hardware resource and power budget are very limited, and on-device machine learning is challenging; retraining the model on-device is even more difficult. We make machine learning efficient and fit tiny devices (TinyML). We holistically developed a stack of techniques to (1) automatically synthesize efficient and tiny neural architectures given hardware constraints, outperforming the human design while requiring less engineer efforts; (2) train the model with tiny amount of data without losing accuracy, with better data efficiency; (3) compress the model and co-design the inference framework to fit tiny edge devices; (4) retrain the model locally on edge devices and customize for new data with tiny memory resources. We uncover new design insights under resource constraints. Our research is highlighted by full-stack optimizations, including the neural network topology, inference library, and the hardware architecture, which allows a larger design space to unearth the underlying principles.
Modern deep learning requires a massive amount of computational resource, carbon footprint, and engineering efforts. On mobile devices, the hardware resource and power budget are very limited, and on-device machine learning is challenging; retraining the model on-device is even more difficult. We make machine learning efficient and fit tiny devices (TinyML). We holistically developed a stack of techniques to (1) automatically synthesize efficient and tiny neural architectures given hardware constraints, outperforming the human design while requiring less engineer efforts; (2) train the model with tiny amount of data without losing accuracy, with better data efficiency; (3) compress the model and co-design the inference framework to fit tiny edge devices; (4) retrain the model locally on edge devices and customize for new data with tiny memory resources. We uncover new design insights under resource constraints. Our research is highlighted by full-stack optimizations, including the neural network topology, inference library, and the hardware architecture, which allows a larger design space to unearth the underlying principles.
Partially funded by the MIT-IBM Watson AI Lab, and IBM Research.
Related Publications
TinyTL: Reduce Activations, Not Trainable Parameters for Efficient On-Device Learning, NeurIPS 2020
Delayed Gradient Averaging: Tolerate the Communication Latency in Federated Learning, NeurIPS 2021
Network Augmentation for Tiny Deep Learning, ICLR 2022
Explore

AI Tool Generates High-Quality Images Faster Than State-of-the-Art Approaches
Adam Zewe | MIT News
Researchers fuse the best of two popular methods to create an image generator that uses less energy and can run locally on a laptop or smartphone.

New Security Protocol Shields Data From Attackers During Cloud-based Computation
Adam Zewe | MIT News
The technique leverages quantum properties of light to guarantee security while preserving the accuracy of a deep-learning model.

New Technique Helps Robots Pack Objects into a Tight Space
Adam Zewe | MIT News
Researchers coaxed a family of generative AI models to work together to solve multistep robot manipulation problems.